

Consistent Hashing
In distributed systems, efficiently distributing data or load across multiple servers is critical. Two common methods for achieving this are Simple Hashing and Consistent Hashing. Let's look into how each method works and compare their advantages and disadvantages.
1. Simple Hashing
Simple Hashing uses a hash function h(k) to map a data item with key 'k' to an integer value. This value is then used to determine the server index by performing a modulo operation with the number of servers, N:
server_index = h(k) % N
The data is stored on the server with the corresponding index.
Example:
Consider 4 servers indexed 0, 1, 2, and 3. For a data item with key "user1234", the hash function might produce a value of 15. The server index is calculated as:
15 % 4 = 3
Thus, "user1234" would be stored on server 3.
Drawback:
When a new server is added (increasing N), all data needs to be remapped using the new value of N:
server_index = h(k) % (N + 1)
This results in a significant reshuffling of data and invalidation of caches, leading to inefficiency and potential downtime.
2. Consistent Hashing
Consistent Hashing addresses the drawbacks of Simple Hashing by minimizing data reallocation when servers are added or removed. Instead of a linear array, Consistent Hashing uses a circular array (or hash ring).
How it works:
Hash the Servers: Each server (identified by server name or IP) is hashed and placed on the circular array.
Hash the Data: Each data key is also hashed and placed on the ring.
Locate the Server: To find the server for a particular data key, move clockwise from the data key's position until a server is encountered.
Example:
With servers placed on a circular array, the key is mapped directly on the ring. For instance, if the servers are s0, s1, s2, and s3, and a new server s4 is added:
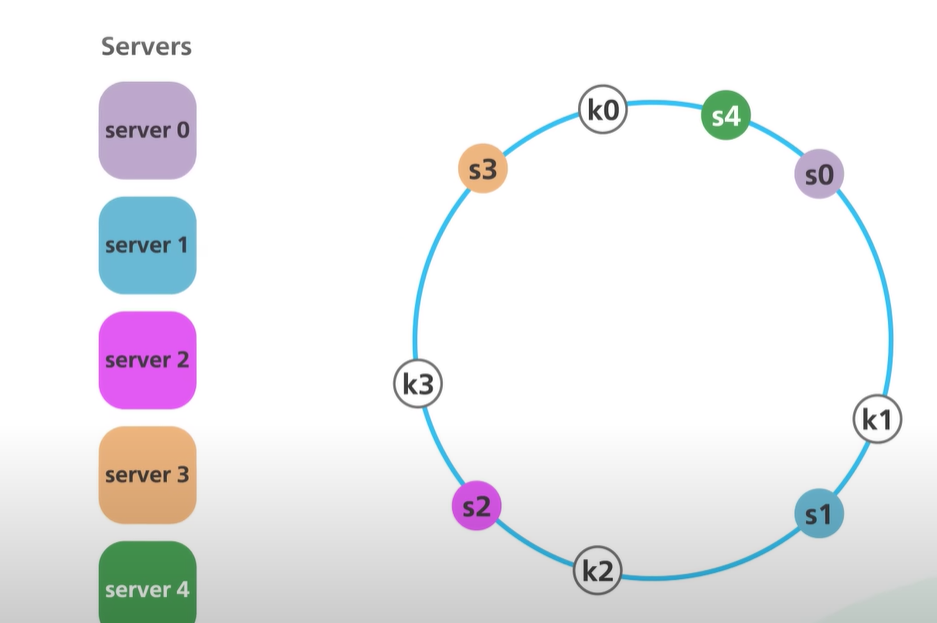
When s4 is inserted to the left of s0, only the data key k0 needs to be moved from s0 to s4. Other keys remain unaffected, significantly reducing the need for data redistribution.
Conclusion
Simple Hashing: Easy to implement but causes massive reshuffling of data when servers are added or removed, leading to inefficiency.
Consistent Hashing: Efficient in handling changes in the number of servers, requiring only a fraction of the data to be redistributed. This reduces cache invalidation and improves overall system performance.
Visual Comparison:
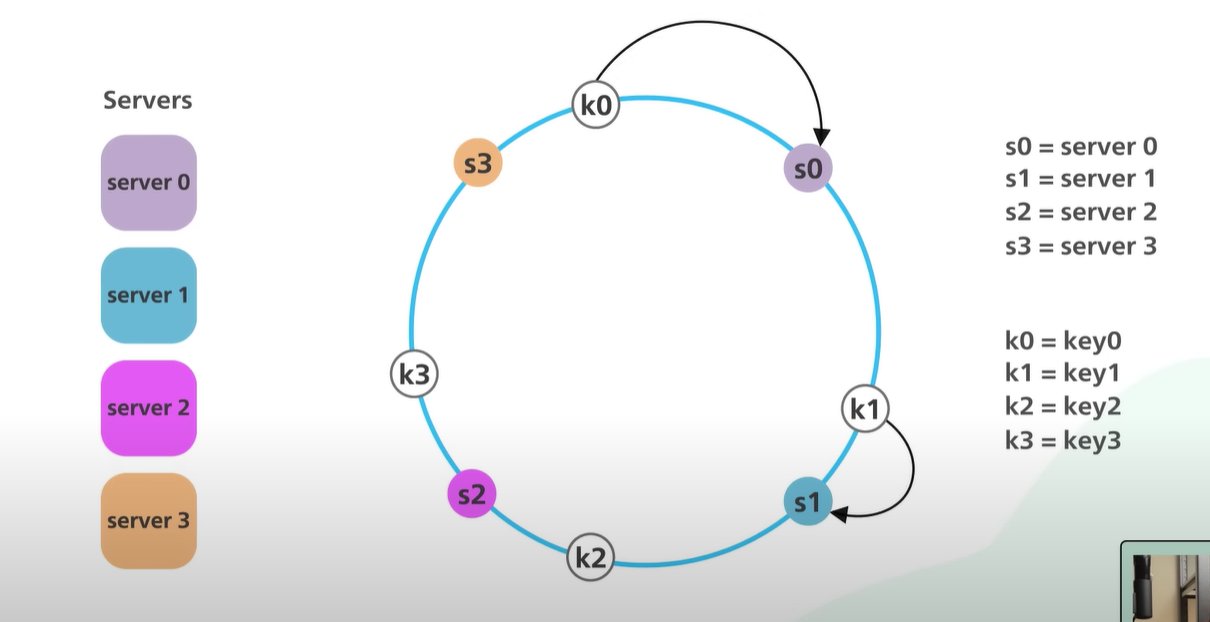
By adopting Consistent Hashing, systems can achieve better scalability and robustness, ensuring minimal disruption during server changes. This makes it a preferred choice for distributed data storage and load balancing in modern distributed systems.
image credit: BytesBytesGo




